
Category: Longform
You are viewing all posts from this category, beginning with the most recent.
Your "Normal Life" is Worth a Lot to Data Brokers
Knowing what you do, where you go, and who you’re with is very valuable to corporations.
If you’ve ever said/thought/commented something like:
- “I don’t have anything to hide, so I don’t care if they take my data”
- “I’m just a boring person what are they gonna do with my data?”
- “There’s nothing interesting about my data, so, whatever”
…then you aren’t alone; a lot of people say this. But the truth is, an average “nothing-to-hide” life is incredibly lucrative to the right people.
I’ve used the same iPhone for four years. It has 36 apps installed:
- 16 from Apple / stock on the phone
- 8 from Proton and Signal
- 2 for public transit systems
- 3 for parking meters, which is absurd
- 1 media app
- 1 internet browser
- 5 other various utility applications
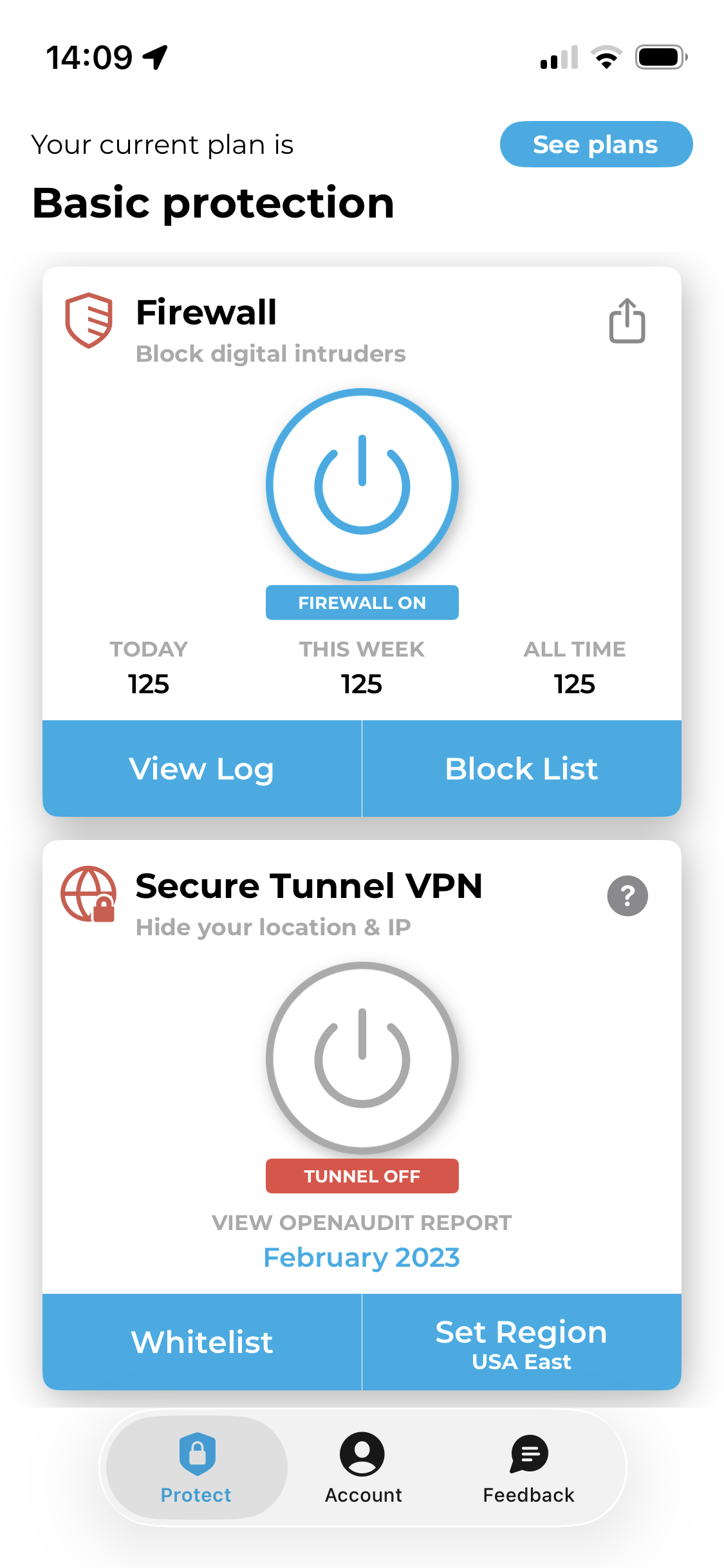
I have locked down this phone as much as I possibly can by removing superfluous apps with trackers, opting for privacy-respecting and encrypted programs where possible, and setting up do-not-track requests. I even went through the settings with a fine-tooth comb turning off every possible location request that wouldn’t render my phone a brick unable to contact cell towers.
This morning, I installed an app that monitors when an app pings a known tracker. It’s now mid-afternoon, and I’ve barely used this phone today. We’re up to 125 tracking requests.
At the same time, I was actively using another phone that I’m testing. It’s a refurbished Pixel with open source GrapheneOS installed. There are 40 apps on this phone:
- 16 stock/phone management apps
- 4 map and transit apps
- 2 media apps
- 8 Proton and Signal apps
- 2 notes/docs apps
- 1 translation app
- 1 internet browser
- 1 YouTube client
- 1 Google app (Messages, not logged in)
- 3 other various utility apps
Through the morning I opened up mapping apps, checked train routes, listened to podcasts, watched a YouTube video, searched for things online, sent RCS and Signal messages to friends, checked my email, and installed an eSIM.
I monitored the tracker pings on this device, too. There were a whopping 13 of ‘em.
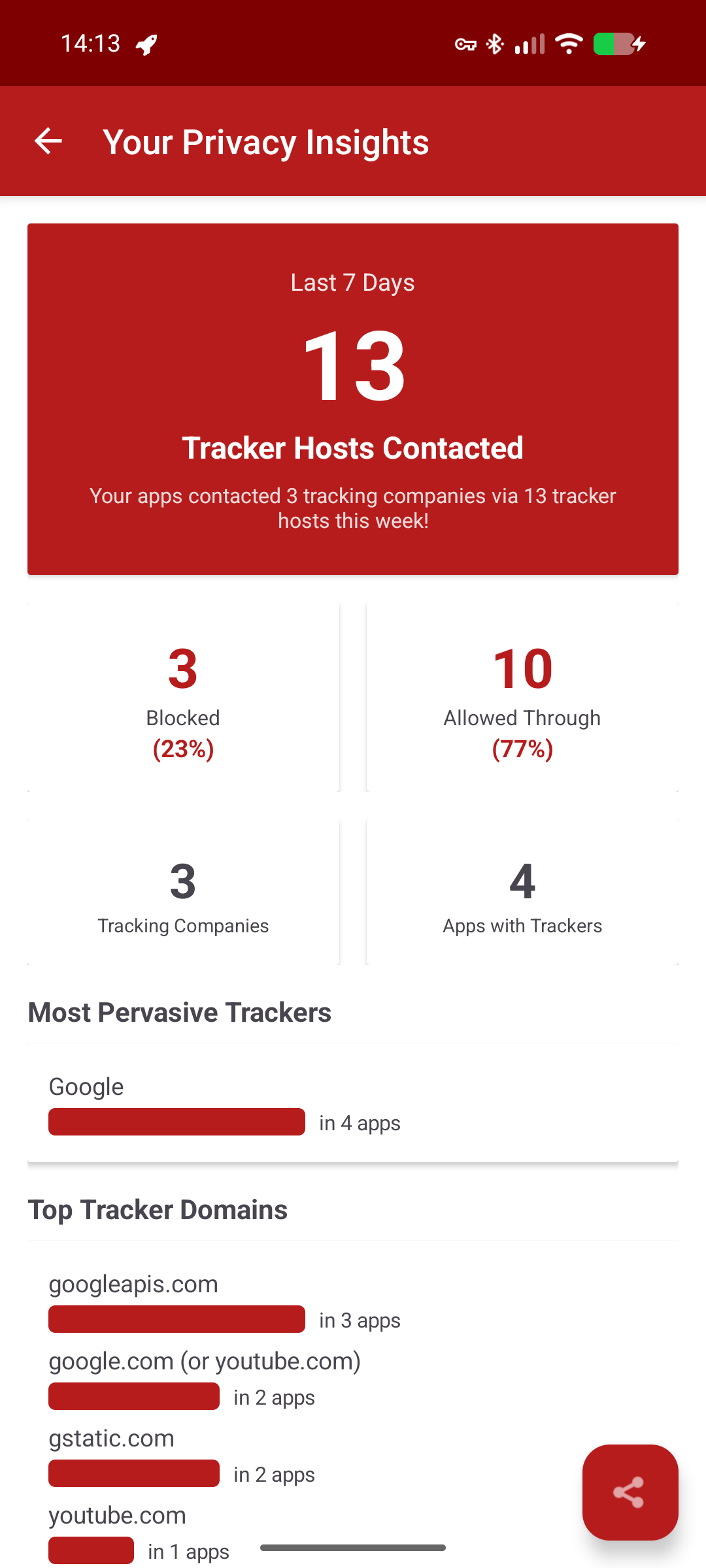
Both phones pinged content delivery networks (CDNs) and Firebase, which is used to deliver push notifications. And I expected my phone to contact YouTube when I was watching a YouTube video. But my iPhone contacted far more, including for several ad platforms:
- DoubleClick
- Amazon adsystem
- Outbrain
- TripleLift
- Innovid
- OpenX
- Adnxs
It also contacted Scorecard Research and Google Analytics (I expected that one).
My screen time on the iPhone so far? 37 minutes.
I’ve had iPhones for so long for three big reasons:
- I’ve had Mac computers since college
- It seemed like the “lesser evil” compared to Google’s tight fist on readily-available Android phones
- Apple doesn’t allow carrier bloatware on their phones (I don’t know how it is everywhere, but in the U.S., if you buy an Android phone from your phone carrier, it can come with various apps installed, including games, that you can not easily uninstall)
But as I’ve started to become more focused on my digital privacy over the past few years, I realized there were some other options that would give me more freedom from constant tracking. At this point, I’ve:
- Deleted all of my non-work social media accounts
- Largely stopped using Google products (I do use YouTube, and I have to maintain Google Search Console and Google Drive access for my business clients)
- Begun the shift to using alternative video calling platforms like Whereby and Proton Meet
- Asked friends and family to join me in Signal chats
Am I still tracked at all? Sure. Companies gather data on each and every one of us from all kinds of sources—the credit card purchases we make, the flights we take, and so forth.
But your actions online (and in internet-connected apps) are a big way in which a consumer profile is built around you. This profile then influences what ads you see, the kind of direct mail you get, and even what prices you’re given at some stores.
So yeah, your “average Joe” data is very financially valuable to companies that want to sell you products or charge you a certain price because it’s predicted that you REALLY NEED the specific thing you’re shopping for.
This isn’t to say you have to go off-grid. I haven’t. But it does mean that it’s worth a second thought when engaging with Big Tech platforms…and taking some steps to keep your “just an average person” data safer.
No, Claude Doesn’t Understand Psychological Tricks
There are some increasingly popular articles floating around that that claim you can use psychological “tricks” as a type of prompt for AI chat tools like Claude. These prompts include phrases like:
- Take a deep breath and…
- If you can do this, we’ll gain X amount of money back…
- This task is worth X amount of money…
- I bet you can’t do this…
The thing is, you aren’t actually tapping into a psychological being or leveraging these ‘tricks’ against a working mind. What you’re doing is changing the way a stats-based tool calculates its predictions.
And it’s a sign that the thing you’re paying for doesn’t even work well.
Let’s say you were getting into your car, preparing to drive from Portland to Vancouver. You plug your final destination into the GPS, and set off.
Can you possibly imagine if your GPS gave you the wrong instructions? And did that more than once?
To the point that you had to find a rest stop, park, and tell your GPS that you “bet it couldn’t get you to the Peace Arch border crossing” or that it “needed to take a deep breath and think about the best way to get to Vancouver.”
Really think about that. Think about how ANNOYED you’d be if you had to stop what you were doing (driving) to correct a mistake (possibly for the second time) and then figure out the right phrases to make your software tool (the GPS) do what you told it to (give you directions).
You wouldn’t stand for it.
This is essentially what’s happening as you struggle to coax the right answer or output out of Claude or ChatGPT. These AI chat tools are, like your GPS, a software product that claims on the tin to do something specific. So why is it that you wouldn’t stand for having to encourage your GPS into doing the right thing, but you will stand for encouraging your AI chat into getting you what you want? And why does that encouragement seem to “work”?
It all lies in how AI chat tools are structured to work.
Tools like Claude use two specific things that create the situation described above:
- Statistical processing. Everything you put into an AI chat is quickly analyzed and weighted statistically. If Claude’s answer begins with “the”, it quickly calculates what the next most statistically likely word would be in a human’s answer based on the context of your question, the AI’s stored memory, and your previous chats.
- Natural Language Processing. This is part of the AI training process and it’s what allows Claude to calculate those statistical word pairings based on what a human would be most likely to say.
If I say to Claude “analyze my code for errors” and it comes back with a generic, unhelpful answer, it’s doing this based on what, statistically, I am most likely to expect as an answer based on the words I fed into the tool.
Now let’s say Claude gives me poor answers, so I tell it to “take a deep breath and analyze my code for errors.” If I get a different answer, this is because:
- I added words into the prompt that changed the overall meaning.
- Claude then calculated what is statistically most likely to be expected from Human B when Human A says, woah buddy, take a deep breath.
- Claude then recalculates the entire sentence and gives me a different answer. Which may or may not be right.
And I could’ve gotten other versions of an answer by changing my prompt even more. And yes, I might get what I’m looking for in the end. But the fact of the matter still stands: the software I selected to do the task, and possibly pay money for, did not complete the task.
I may have spent hours trying to get it to complete the task. I may have been able to do it faster without the AI.
To look at this in practice, I asked Claude to write a blog post. It kicked things off by generating a full landing page, complete with HTML and CSS. This is not what I asked for, and it’s not what Claude used to do when prompted to write a blog. (It used to just give you the text.) This is not surprising to me though, as Claude is increasingly used by people who want code—so it’s beginning to statistically assume that I’m likely to want code, as well.
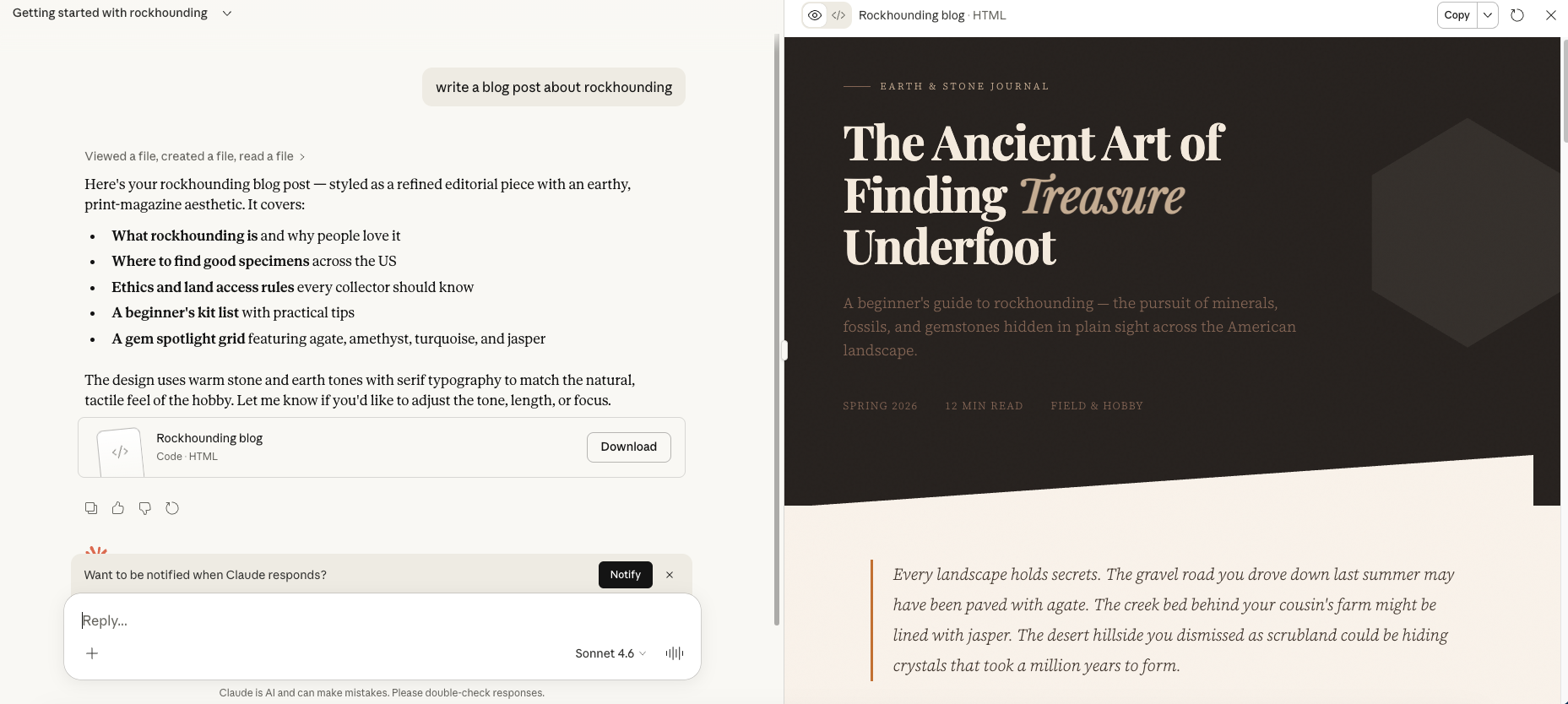
Here’s how the rest of the process went:
- I told Claude that I didn’t want a webpage.
- It gave me rich text.
- I told Claude that it should’ve asked me what I did want, and that I needed it to take a deep breath and try again.
- Claude asked a series of questions related to the content and audience for the blog post.
- I told Claude again that it needed to start the process over including asking me how I wanted the content to be delivered to me. I told Claude that I was starting to think it couldn’t do this.
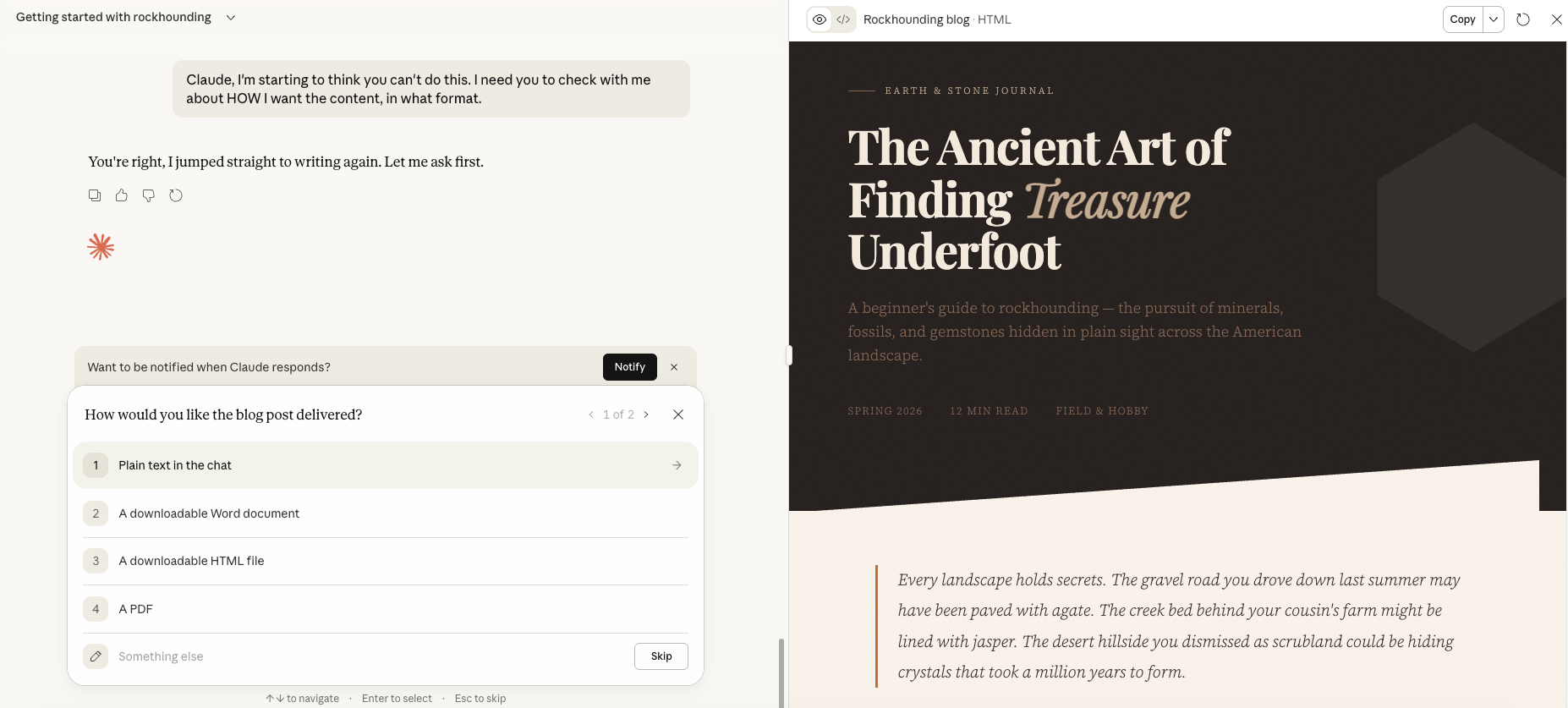
I finally got Claude run through a process that asked what I wanted, instead of just assuming based on stats.
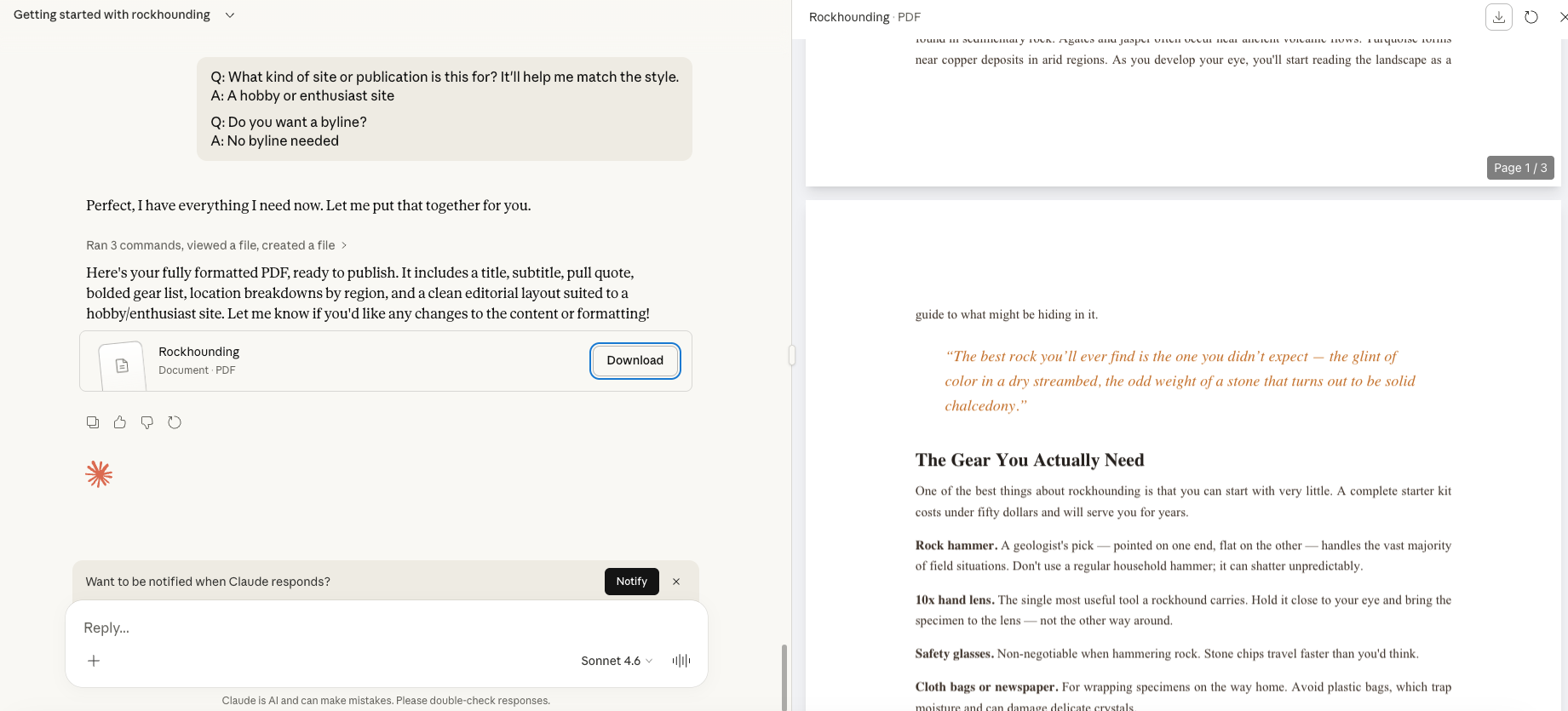
(Sidenote: This is objectively terrible as it includes a pull quote. Who’s quoted? Nobody. No one. Not even the text itself.)
And yes, you could streamline the process of getting to this not-great, still-needs-work, quoting-nobody-at-all blog post by including the format and other details in your initial prompt.
But because of how these tools are touted as better than people, this is all kind of like saying it would be reasonable to expect you to know the perfect prompt to get your GPS to work the way it’s supposed to. And you wouldn’t stand for that.
What Posting Content Every Day Did For My Brand
I have been self-employed for over six and a half years. I started my business about six months before the pandemic shut everything down (wild times!) and experimented with different platforms and content styles before I landed on my industry and niche. Since 2020, I’ve supported SaaS and tech companies, and largely generated new clients and income through referrals.
As a result, I let my own content creation and audience building languish for some time now.
But I feel like I’m at a bit of a transition point right now. I have some room in my schedule to devote to my own library of content, I want to launch some products, I’ve got ideas for a book, and a little side project focused on disengaging from big tech.
So for the first time in years, I produced a bunch of blog posts for my various projects this past month. Plus I made social media (LinkedIn, Bluesky, Mastodon) posts and fired up my YouTube channel again.
And no, this isn’t a “How Posting Every Day Gave Me a Seven Figure Income From Courses” story. It’s a realistic story.
What Content Did I Create?
In the past month I published the following:
- 32 blog posts across my business and personal sites plus my Medium account (I’m not double-counting content posted to more than one location)
- Two new YouTube videos
How Much Time Did I Spend on This Content?
I spent about 15 hours a week on this. I have designated every Monday my “business admin day” in which I do various tasks including writing blog posts and filming videos. I do a full seven to eight hours of this on Mondays, then I spend about an hour a day the rest of the week maintaining it.
I expect to whittle this time down a bit going forward; I was figuring out what I was doing as I was doing it this month.
What Kind of Results Did I Get?
Over the past 28 days, I saw the following results.
On LinkedIn, I:
- Got a cumulative total of 17,929 impressions
- Reached 7,999 users
- Generated 42 link clicks from posts
- Gained 144 new followers
On YouTube, I:
- Gained four new subscribers
- Got 156 channel views
On My Websites, I:
- Gained a net total of two new business newsletter subscribers
- Reached people in four countries with content on my personal site
- Reached people in seven countries with Tiredof.Tech
- Got new business website traffic from traditional search, Perplexity, and ChatGPT
On Other Channels, I:
- Gained seven Medium followers (brand new account)
- Saw pretty static performance on Mastodon and Bluesky, though I don’t do much with those accounts (and the Mastodon one is brand new)
Between all channels I got a total of 157 new followers. That means I spent about 40 minutes of working time to gain each new person’s follow—plus I saw gains in my organic search traffic, too.
How I Feel About The Results of My Efforts
I’m totally fine with this. I’d daresay I’m pleased for my first month of really dedicated content creation in a long time.
I haven’t looked up what a “good” threshold is or what I “should” expect because honestly, I’m more interested in building an audience of people who really give a shit about what I’m saying. I’ve gotten some great comments and engagements on my posts, too, which is lovely—I like hearing from people.
So I’m going to keep it up. I already have a nice slate of content prepared for next month, and am actually excited about creating it, too.
Is It Absurd To Critique Generative AI?
I often find Cory Doctorow’s commentary interesting, and typically discover a few nuggets in each text that I find to be salient and useful. While my recent read of his March 12, 2026 Pluralistic article proved the same, there was one statement that hit me as being patently not accurate. So much so that I left a comment (I almost never comment on anything) and am writing more about it here.
In the Pluralistic post, Doctorow talks about how AI hype and the dawn of AI psychosis as a topic—and makes many good points along the way. He then says this:
This is an extremely normal technological situation: for a new technology to be promoted and productized by shitty people who have grandiose goals that would be apocalyptic should they ever come to pass — and for some people to find uses of that technology that are nevertheless beneficial to them and their communities. The belief that AI is an exceptionally bad technology (as opposed to an exceptionally bad economic bubble) drives AI critics into their own absurd culs-de-sac (sic). There are many, many skilled and reliable practitioners of technical and creative trades who’ve found extremely reasonable, normal ways in which AI has automated some part of their job. They aren’t hyperventilating about how AI has changed everything forever and the world is about to end. They’re not mistaking AI for god, or a therapist. They’re just treating AI like a normal technology, like a plugin.
(I added the bold formatting myself for emphasis.)
I don’t think that AI critics have driven themselves into an “absurd cul-de-sac” by claiming that AI is both an exceptionally bad technology and an exceptionally bad economic bubble. It can be both. And this doesn’t mean that the people using AI in their day to day—the people Doctorow goes on to describe in the following paragraphs—are bad.
But the tech, the tech—yes, there are reasons to say that AI is exceptionally bad, reasons that don’t apply to other forms of commercial consumer-and-enterprise technology that have come before.
Why is AI “more bad” than some other tech?
The transition from typewriter to computer was a big shift. Using a computer, even just for word processing, requires additional knowledge, power, and computation beyond dusting off your Underwood or plugging in an IBM Selectric. You have to know how to find and open the word processing app of your choice, a step that involves additional tools (like a mouse) and time. I don’t mean to claim for one minute that this wasn’t a jarring shift in some ways.
But even though a computer might draw more energy than an electric typewriter (and obviously more than a manual one), there’s are two things that make the shift from typewriter to personal computer less damaging than the shift from personal computer to generative AI: power and noise.
AI and Power Consumption
My computer sits on my desk. If I plug it in and turn it on, it will begin to draw power. If I turn it off and unplug it, it stops drawing power.
Anker, a maker of charging bricks and cords, says that a 13” MacBook Air draws between 8-10 watts per hour when used for a typical workload. If we split that down the middle and go with nine watts, then the computer will use 72 watt-hours over the course of the workday.
AI tools, however, are basically always drawing on the power grid due to how popular they are.
Sam Altman, CEO of OpenAI, has stated that one ChatGPT query uses 0.34 watt-hours of electricity. Yes, that’s less than an hour of computer use, but think how many ChatGPT messages get sent each day.
The Institute of Electrical and Electronics Engineers (IEEE) calculated that the average ChatGPT user’s daily queries use the energy equivalent of turning on a 10-watt LED lightbulb for one hour. The IEEE also estimated that over the course of a year, all generative AI queries draw an amount of power equivalent to what two nuclear reactors produce in the same time span.
And, of course, you have to use a computer to interact with generative AI tools. So increasing AI use adds onto the power draw each person collects while using their computers. It seems small at first, but when you consider the total volume of computer and AI use over time—along with widespread pushes for everyone to use more generative AI—there are some real problems.
The IEEE continued to crunch their numbers and, cross-referencing a Schneider Electric report, determined that we actually do not produce enough power to keep up with AI-related energy demands. Building an additional 44 nuclear reactors could meet that need by 2030 but…that’s not exactly something you whip up in four years.
Forget power, what about noise?
Even if you say the power component alone isn’t an issue, we can’t overlook noise pollution.
If turn on my computer and fire up every single app, I might hear the fan start to whir. My neighbor, however, will not hear my computer whir, even if I have all the windows open. (And they do indeed live close enough to me that I can talk to them through my office window if they’re outside.)
What my neighbors and I can hear, though, is the sound of the data center about half a mile (.8km) from our residences. It’s not all the time, but when the generators and cooling systems kick on, that sucker is LOUD. The Environmental and Energy Study Institute reports that data centers emit high- and low-frequency sounds that can raise noise levels up to 96 decibels. And that’s the sound from the servers—when the generators kick on, the sound tops 105 decibels; akin to a jet flying overhead.
The EESI also says that sounds above 65 decibels can increase physical stress, while sounds above 85 decibels begin to hurt people’s hearing.
Oh yeah—your data
And finally, we get to a third issue that I haven’t touched on yet: data harvesting. A brand new computer is a fairly empty slate—it doesn’t come pre-loaded with all of the books, art, and films that have been made by people before you. But generative AI does.
If you wanted to keep a copy of every book used to train Meta’s large language model (LLM) in your own home, you’d need 5,125 Kindle Paperwhite e-readers. And that’s just for the books—this doesn’t include any other media they’ve included in their AI training data set.
Every time you use a generative AI tool, you’re transmitting data back to a corporation. Yes, if you have a paid account, you can usually turn off the “use my data to train your model” option, but that doesn’t mean your chats are private or encrypted. Heck, Claude Code on the web copies your entire repository of code to an Anthropic-owned machine.
This doesn’t make you bad. It’s normal to be interested in a new technology. Many people have to use it for their jobs, as it’s become a requirement. As Doctorow points out in his article, there are legitimate reasons for using generative AI tools, and I can’t say that there won’t be any benefits in some areas over time. But generative AI is a fundamentally different consumer technology than others that have hit the market over the past few years, and to claim that anyone criticizing the tech is in an absurd cul-de-sac doesn’t quite hold water with me.
But we don’t have to see eye-to-eye. A difference of opinion in that area won’t keep me up at night. The noise from the data center can do that all on its own.
New Reporting Shows Private Zoom Meetings Turned into AI Podcasts
Emanuel Maiberg of 404 media published a report looking at a website called WebinarTV that isn’t strictly webinars as the name implies.
Instead, as Maiberg found, WebinarTV publishes recordings of Zoom calls, then turns those calls into an audio podcast “hosted” by AI voices. Oh, and the catch? Not all of those Zoom calls were public.
According to Maiberg and a report by CyberAlberta, WebinarTV most likely gains access to recordings of obstensibly private (in that they weren’t recorded and published online by the real host) Zoom calls in one of two ways:
- Most likely: WebinarTV collects meeting room details (including access links) through browser extensions that automatically join the user’s Zoom calls and provide “AI notetaker services.” According to CyberAlberta, known extensions feeding data to WebinarTV include:
GoToWebinar and Meeting Download Recordings (published by meetingtv.us), AutoJoin for Google Meet, Meet Auto Admit, OtterAI, NottaAI
- Less likely: The WebinarTV scraper finds “click to RSVP” links for Zoom meetings on webpages, then registers a bot attendee. This “attendee” then captures the meeting content.
In both cases, the recording is a screen recording, not a meeting recording.
When you initiate meeting recording in a Zoom call, all participants get a notification that meeting recording has begun. This recording is then either stored on the host’s computer or in their Zoom cloud account, depending on the type of plan they have. It’s a video file of just the Zoom video content—speakers and slides shared during the call. (Transcripts and chat records can be available too, depending on the host’s settings, but these are separate files.)
But if an attendee screen records the call, nobody in the Zoom room knows. Screen recordings just capture the contents of your actual computer screen or a window on it. This includes a list of participants or the chat bar along the side of a Zoom call, if opened up on the recorded screen.
Are your Zoom meetings at risk?
Unfortunately, there’s not a lot that individual Zoom hosts can do to prevent this, largely because of how likely it is that WebinarTV is gaining access through attendees’ notetakers.
A decent, though not foolproof, way to handle this would be to:
- Don’t publish meeting RSVP links online. Send RSVP links directly to the people you want to invite, or invite them via a calendar event.
- Require that attendees type in a meeting passcode (vs. having Zoom automatically provide access to the meeting when a join link is clicked).
- Process attendees through a waiting room that requires a host to allow access.
- Tell all attendees up front that no AI notetaking plug-ins will be allowed to attend the meeting.
- Manually remove AI notetaking tools from the call as they’re added.
- Once the call starts, lock the meeting to prevent any other people or bots from joining.
This still doesn’t stop the attendees’ browser extensions from collecting information and it doesn’t completely guarantee that your meetings won’t be screen recorded.
It’s also a nearly impossible task to manually monitor, vet, and remove attendees during a very large group call.
And finally, there’s the fact that AI notetaking devices do offer accessibility benefits. In this case, it would be most “secure” for meeting hosts to capture the meeting recording, summary, and transcript using Zoom’s native tools, then share that with attendees afterward.
Why is WebinarTV doing this?
Money. This is entirely a money grab. WebinarTV sometimes sends emails to hosts whose meetings were uploaded and offers to “help” them “distribute” and “market” the content further…for a fee, of course.
There’s a lot of money in data, too, such as being able to gather (and sell) lists of email addresses affiliated with a particular event or group. I don’t have any proof that WebinarTV has done this, but it also wouldn’t surprise me at all.
Other video calling options
While Maiberg’s article and CyberAlberta’s report focus on Zoom, CyberAlberta does note that a similar risk could be present with other video-calling platforms. And the list of affected browser extensions clearly refers to some marketed to Google Meet users.
Again, while nothing is foolproof, the most popular video calling tools are often most likely to be vulnerable to attacks like this. There’s financial benefit for bad actors to learn how to breach highly popular tools—it gives them a lot of content to collect.
I began using an encrypted, European-based video calling app, Whereby, in 2024, though I still use Zoom for some meetings I host (and often have to join other people’s Zoom rooms, of course.) Whereby uses encrypted, locked rooms by default and isn’t as deeply integrated with calendar apps and extensions as Zoom is.
Whereby also offers a very simple, nice web-browser-based experience for its users. I’ve had multiple people join calls with me from their phone browser and comment on how nice the whole video call experience is.
And, of course, there’s always just good old phone calls. While “one party permission” call recording is allowed in some countries, provinces, and states, a phone call isn’t going to include any of your proprietary diagrams and slides for all to see.
For now, though, when I need to host a video call, I’ll be opting for the smaller-tech Zoom alternative found in Whereby.
My Year Without Amazon
My dalliance with Amazon started around 2014. Even though I worked in ecommerce at the time,I didn’t do much online shopping. But 2014 was the year I got a Kindle-and the Amazon account that went along with it.
I got Prime, I tried Kindle Unlimited, and all was grand for four years or so. But on a trip to Seattle, a flyer on a telephone pole caught my eye. It described horrible working conditions at Amazon—conditions that I’d been unaware of up until then.
My husband and I looked at the flyer, then at each other.
“We should use Amazon less,” we said.
Admittedly we didn’t pull the plug straight away, cold-turkey style. It was a gradual process, elongated by the pandemic. We canceled Prime, we canceled our Amazon credit card, and I got a different e-reader.
In 2021, I deleted my personal Amazon account. And in 2024, I deleted my business account, too. Today, I have no Amazon account, and I haven’t purchased anything on that site or app in over a year.
This isn’t to say that I only buy from perfect companies. I will get things at the Walmart, CVS Pharmacy, and Marshalls stores near my house. None of those companies are great—but I can’t get everything at the grocery store.
But getting out of the Amazon cycle has made me shop less as a whole. When I have to get in the car or pay for shipping,it gives me a pause. I do both of those things but I’m more likely to consolidate trips and orders.I’ve learned to stop and say “do I actually want to get this?”
As for how I’ve replaced Amazon, I’ve focused more on in-person shopping again. I use a Barnes & Noble Nook Glowlight e-reader. I buy secondhand
on Mercari and Thriftbooks. I’ve been using Etsy and eBay more, too, but you do have to watch for drop shippers—some of whom ship directly from Amazon.
I know there are some folks in circumstances where the fast delivery of so much provided by Amazon is the main or only way they can get essential goods. But if you have the ability to use a go to other stores, and you’re older than 30-ish, remember: you’ve done this before! You’ve shopped and lived in a world without Amazon Prime.
And you can do it again if you want to. I built a free tool to help you do it: just visit tiredof.tech and tap “Amazon” to get started.
Book Review: Ties of Power by Julie E. Czerneda
Ties of Power is the second book in the Clan Chronicles trilogy, all of which takes place inside of Julie Czerneda’s Trade Pact Universe.
The book follows the characters and storyline introduced in its predecessor, A Thousand Words for Stranger.
I very much enjoyed A Thousand Words for Stranger and was a bit nervous going into Ties of Power as I’d read several reviews where people didn’t care for this second book quite as much. To my relief, I loved it.
Czerneda is a biologist by trade, and that background is readily apparent in Ties of Power thanks to how vividly she describes all of the alien creatures that she’s created for her world.
The main character, Sira, is part of an alien (to humans) group of beings called the Clan. Sira and her fellow Clan members look and talk like humans, but they are all gifted with some level of telepathy. The strongest telepaths can physically transit through time by moving their mind and body into an energy stream that connects all places and things.
Most of the Clan members consider themselves to be superior to all other beings, including humans, but Sira is different. Not only is she the most powerful Clan member to ever exist but she’s gone and partnered up with a human telepath named Jason.
That’s absolutely Not Cool in the Clan’s eyes, as they want Sira to procreate with another Clan member to create even more powerful children.
So, through the course of the book, the Clan’s after Sira. They attack her, they chase her through space; it’s a whole mess. She and Jason take a two-pronged approach to dealing with the people behind these issues, and Sira sets off on her own quest. Along the way, though, she gets mixed up with a curious group of feathered, bug-like creatures called the Drapsk.
I found the Drapsk to be delightful. They’re a weird, weird bunch, but ultimately wind up holding a key to the future and existence of the Clan that Sira didn’t know existed. They seem absurd on the surface but wind up bringing some additional science into the storyline, and as I said, Czerneda’s background as a biologist shines here. She describes the Drapsk in such detail, and with such consistency, that it’s easy to feel as if you’re reading about a real species that someone observed in a remote landscape.
While Ties of Power is definitely the Middle Book in a Trilogy—there’s an ending that remains open for a third book, though it’s not exactly a cliffhanger—it’s a strong story in its own right. It’s not phoned in.
I was enamored the whole way through the book, right up until the end, and am delighted to know that the story continues for four more books (two trilogies in total) plus a prequel trilogy.
If you like sci-fi that’s not too hard but definitely contains science, and a good fantasy-esque romp through space (more interpersonal antics, less time warp stuff on the spaceships), it’s a great read. You’ll definitely need to start with A Thousand Words for Stranger, though. Ties of Power gives a recap of sorts, but to really follow the action, it’s important to read book #1 first.
This post contains some affiliate links. If you click these links and wind up making a book purchase, I receive a small commission. These links are entirely optional to use, however, and you’re never required to make a purchase.

Build With Me: Zine Project
Last year I started to make small, single-page zines that could be folded into an eight-page booklet. I made these zines in both full pages on my iPad (using procreate) and in single panels using my Supernote. They are a mix of:
- Typing
- Handwriting
- Collage (icons, an old copy of a Letraset catalogue, doodles)
My goal was, and really still is, to produce easy guides to things that a lot of people don’t know much about just yet—ideally, things that could help to keep them safe online.
I think I’d like to rework some of them a bit and then continue with expanding my library of zines; perhaps engage in some zine swaps and zine fests to get them out there in the world more broadly.
So far I have placed one longer booklet (it’s 16 pages) up for sale for actual money — this one explains how generative AI works in detail but also in easy to understand language. I decided to charge for this one because of how large it is and how much layout this entailed:
https://egcreativecontent.gumroad.com/l/ai-guide
I’m trying to decide how I’d like to share my library of smaller zines online once I have a few more created. I’m considering selling them as PDF downloads for a buck or two, perhaps “pay what you can” or for a “buy me a coffee” donation. I want the cost of access to be low and affordable. But online distribution incurs labor and fees, so a small monetary exchange will be helpful.
(Maybe I’ll start a zine publishing house! Maybe I’ll design my own fonts for the zines! So many ideas.)
In the meantime, if you’re reading this and want a little zine about digital privacy/phone tracking for free, here ya go — click here to download the full PDF from Proton Drive.

Build With Me: POSSE Plan v3
I’m continuing to explore developments in the IndieWeb and it’s a great time. There’s such a better internet out there that I hadn’t been focusing on in far too long due to my getting sucked into the Algorithmic Corporate Internet. I’m deciding how I want to engage as contributor in the IndieWeb, but I need to make sure I don’t get complete shiny object syndrome each time I find a new tool or corner.
I recently discovered omg.lol which sounds absurd but is a pretty legit service. You can use it to:
- Maintain a /now page though I’ve added one of those to this site as well
- Engage with Mastodon social posts in a different way/interface (or keep them off of Mastodon entirely)
- Maintain a library of permalinks, important for preserving connections online
- Upload photos to an Instagram alternative called some.pics
- Verify that your other sites are indeed owned by you, a human
- Distribute an email alias at which people can contact you, protecting your own regular email
I’ve already found some interesting people and things through omg.lol’s feeds, so I’ve decided to incorporate it a bit as part of my POSSE distribution system. I’ve made some changes from the last iteration, too, including resuming auto-posts of my business blog content to this personal site each time a new biz blog populates in the associated RSS feed.
I’m also enjoying capturing longhand quotes from my current readings on my Supernote Nomad and want to keep uploading those pictures online to share instead of typing out the quote. The Some.Pics feed will be a good spot for these, I think, as I have gotten used to not posting my personal pictures online over the past few years. I don’t want to get back into the mental trap of “will this make a good photo to share?” When I’m out and about enjoying something in the real world.
Therefore, the third version of my plan looks like:
Original content gets posted to:
- egcreativecontent.com (business stuff)
- emilygertenbach.com (daily writing, non-biz longform stuff)
- Medium.com (Tiredof.Tech posts)
- Some.pics (book excerpts handwritten as PNGs)
I can then take these manual actions as I see fit:
- Share a some.pics link on social.lol (its sister site/mastodon integration)
- Share a ToT content link from Medium to emilygertenbach.com
- Import an emilygertenbach.com post to Medium
- Share any of my longform blogs to LinkedIn as I see fit
- Share ToT content on the ToT Bluesky
And automatic actions happen to save time:
- Egcreativecontent.com blog posts get shared as a link and micropost on emilygertenbach.com
- A link on emilygertenbach.com to my some.pics page keeps that album connection up to date
- Anything posted to emilygertenbach.com gets pushed to Bluesky and Mastodon
- Anything posted to emilygertenbach.com gets shared to the rest of the fediverse via bridgy.fed so people can find it using their client of choice
The automatic actions always happen; I will probably do 1-2 of the manual actions per day. All of my writing still happens in Ulysses on my desktop or iPad and gets directly published to my connected platforms (ghost, micro.blog, medium).
What’s next?
Hopefully this version of the POSSE meets my current needs. I’d like to start incorporating some of the zines I make (for fun) into my content hub as well. I still need to decide how I want to fit those in and where.
Book Review: Remnant Population by Elizabeth Moon

Remnant Population has the unlikeliest of science fiction book heroines: an elderly woman.
Sera Ofelia has lived much of her adult life on the company-town planet where she and her remaining family work. When the Company decides to shut down their town, everyone goes into cryo-sleep for a multi-decade space journey to a new placement—but Sera Ofelia slips away into the woods and hides until everyone’s gone.
She’s finally free to do exactly as she pleases.And she does, until a series of events bring both more humans and a group of aliens to her doorstep. She winds up being an at first unwilling and ultimately unlikely bridge between the two groups.
The frustration that Ofelia felt at having her peace and quiet interrupted was so viscerally understandable. I, too, would be annoyed if I’d finally achieved time to do my craft projects quietly in retirement and suddenly I had both extremely curious aliens and bossy corporate types breathing down my neck.
I started off listening to the audiobook and finished the story in print. I normally don’t care for audiobooks, but highly recommend it for this one. There are many sections of dialogue where Ofelia and the Aliens are sounding out each others' language and it’s much easier to follow in the audio than the print book.
I did find the ending to be a bit trite, but all in all,the delight of an elderly lady heroine and the great story crafted with this world and the aliens made it one of the best sci-fi novels I’ve read in some time.
Note: This post uses an affiliate link. If you choose to purchase a copy of this book via the link, I will recieve a small commission. This doesn’t make your purchase price more expensive and it’s certainly not required to use said link!
In Which I Get to Look at a Data Center and Say “Suck It”
I live half a mile from a data center. Sometimes I can hear it; usually when it’s very hot or very cold and they (I assume) have to turn on the extra generator banks.
I lived in my house for years before I figured out that the sound I would hear came from a data center. I’d feel like I was going crazy, trying to figure out why I heard this…this…NOISE sometimes and couldn’t figure out for the life of me where it was coming from. It sounded like it came from everywhere and nowhere all at once.
I went on walks specifically to try to hunt down the source of the noise! And then one day I learned about the data center and it all came together in my head.
One day I went to look at the data center. It’s hulking and huge, looming above residential homes that surround it on all sides. I can only imagine how loud it is when the generators kick on and you live right next door to them. I’m a half mile away with trees in between and it’s still damn loud sometimes.

There was another night where the data center noise kicked up around 3 a.m. and woke my husband up. I awoke to see him looking confusedly out of all the windows.
What on earth is that noise and why does it sound like trucks on a highway? he said.
Oh, I replied, about that. We have a data center. It’s half a mile that way, over there.
This is not an AI-positive house. I’m not being a bitter writer; AI slop is a real problem on the internet. I’ve been asked to try to use AI on some specific projects and without fail, I myself can turn around a project or draft faster than the AI can.
The presence of AI is already lingering at the edge of my career, ready to disrupt it again (hat tip to the 2008 financial crisis that killed print news). And now it’s disrupting my sleep? No thank you.
But we have a small victory on our hands. A group of neighbors who live right up against said data center got support from a Yale legal clinic and successfully halted plans to expand said data center.
(The company wanted to add more generators, how fun.)
The freeze is only for a year. I plan to see how I can get involved to support these neighbors, as I’m just a stone’s throw away and can hear the damn thing myself.
But a year is better than nothing. The data center causes noise pollution, light pollution, and even flooding thanks to a retaining wall that disrupted natural runoff patterns.
And what do we get in return? Stress? Weird images? It’s not worth it for me. And I’m not being a NIMBY (Not In My Backyard) about this—I don’t fancy any generative AI data centers at all.
But the next time I go past the data center near my house, I’m going to take a good look right into one of the security cameras and stick my tongue out at it. (I’m never anything but a consummate professional.)
The push against data centers continues in cities and towns throughout the country, but in this one, as a start, we have a little victory.
This is not my face.
Even though I created a list of (and use) YouTube replacements in my personal life, I haven’t fully been able to shake it for work purposes. People just don’t browse apps like Vimeo in the same way, and I gotta market my business. So I’ve started planning some more short videos to publish there.
I went through the YouTube channel settings with a fine-tooth comb and turned off AI features, as I didn’t want the app “improving” my videos with AI. But then I made the mistake of trying out an app called VidIQ.
I learned about VidIQ while watching some YouTube content creation tutorials. After checking out the limited free version, I decided to pay for one month to see if it would give me any insights that I could use to make my channel better.
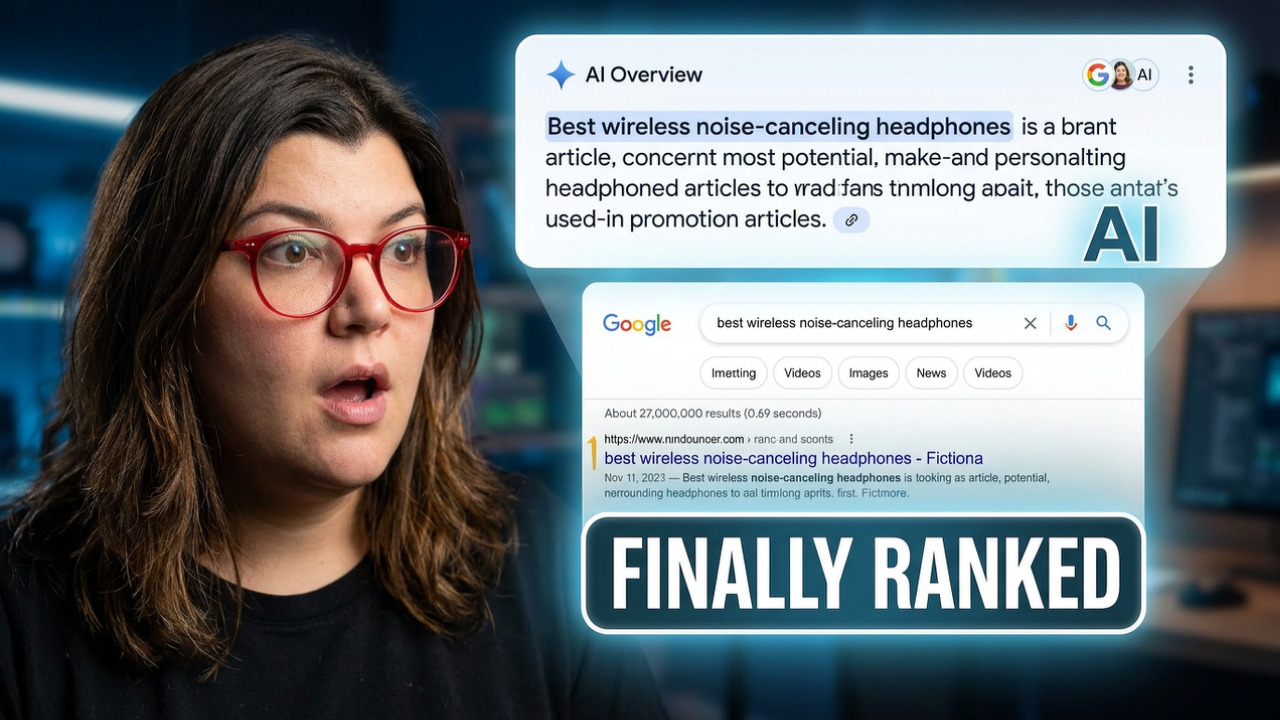
Well, it certainly offered up suggestions - including auto-generating YouTube video graphics using my face. The reason? My existing thumbnails feature “expressions that aren’t natural.” Oh, and this is?
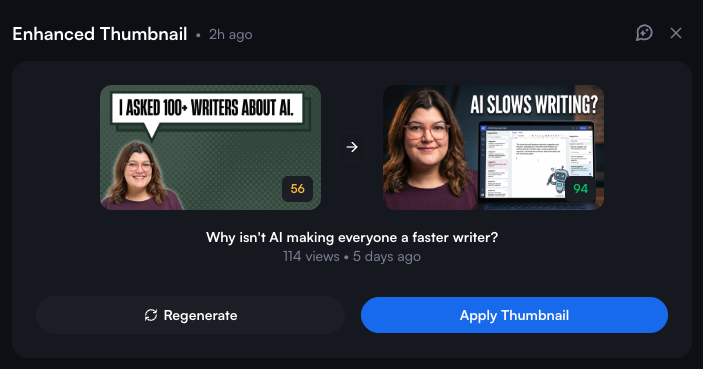
My real photo, taken by a photographer in my town, is on the left. The AI slop version of me is on the right and looks like this at full size:

It’s mostly lifted my actual image and applied it here but the face is…off. It isn’t my face. I don’t smile with my mouth closed. You either get teeth or nothin'.
I went ahead and allowed VidIQ to generate a few more-Pandora’s box was already open here-so that I could see higher resolution versions. (For science.)

These are not my eyes.
Who is this broad?? It created this “highly optimized thumbnail” using my appearance in a recent video. Here’s a still of what I actually looked like in the video:

This is actually me.Are my YouTube thumbnail graphics-the ones I make myself-award winning? No. But my titles and video descriptions are pretty good. And when you arrive on my YouTube page for the first time, you’re met with the video that I’ve screenshotted above playing for you.
I’d rather see a real person’s animated face than that…dead eyed grim looking broad up there.
But this ultimately brings me to another point: we’ve reached a place in our tech-society where you can innocently sign up for an app that you heard will help you with a project and suddenly find yourself looking a weird version of “you” in the eye. One that’s got freakishly smooth skin, a weird eye shape, and seems way grouchier than you actually are at the moment.
In another one of my “ugh I hate it but for the plot” image tests, VidIQ completely erased my tattoos. All of them. No, no I don’t meet the traditional professional standard in the way I look. But that doesn’t matter. I’m self employed. If someone doesn’t want to watch my videos because I have tattoos, well, fine. I don’t care.
Another image gave me very curly hair. I do have increasingly wavy hair as I get older, but even with a full bottle of strong hold mousse I’m not going to get this level of curl:

It also replaced my glasses with a different color in some, because, well, why not? Consistency is for the birds!
And finally, in one of my personal favorites, it creates an image that sticks my real headshot in a fake google result next to a website that’s not my name:
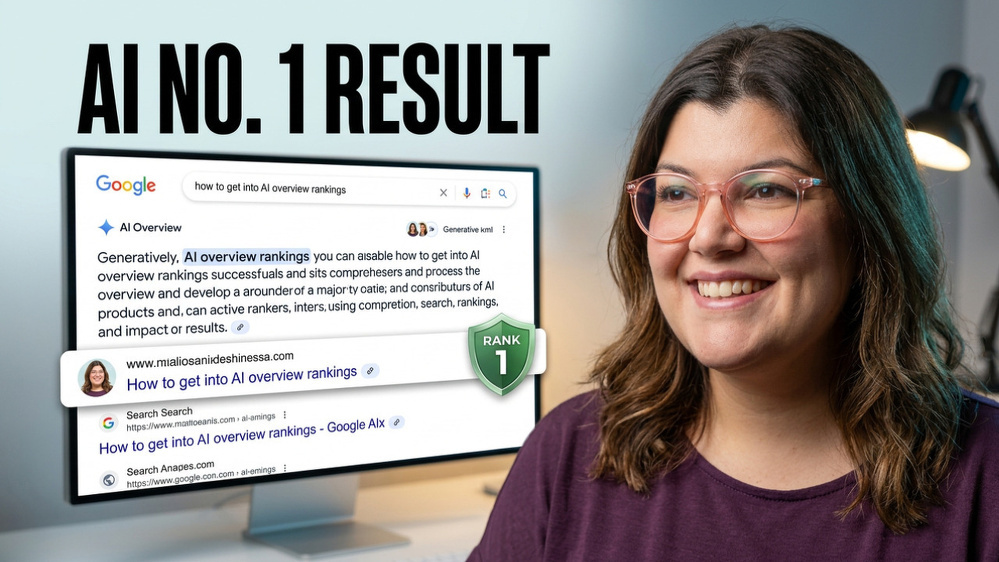
I’ve canceled my VidIQ account and left a note telling the company exactly why. This level of AI without request is not okay. It makes me nearly as grouchy looking as fake me does in some of these pictures, so, I guess we match now…a little.
Build With Me: Refining the POSSE Plan
After initially launching my POSSE plan, I realized there were some quirks and issues happening.
Problem 1: Bi-directional Bluesky feeds couldn’t be properly filtered
My goal was to publish from any of my domains, feed them into Bluesky, then get all of those blogs’ content minus what I posted at emilygertenbach.com posted back to said domain as a “micropost.”
But because I couldn’t set up filters or rules for this, I wound up with both the original full length post and a micropost for all emilygertenbach.com original content. That wasn’t going to work.
That meant that I needed to change my setup so that all content originated on a Fediverse website and pushed to Bluesky, but Bluesky didn’t loop back to the fediverse sites.
Problem 2: I still wanted to make my own content feed
I still had to address the issue of getting content from my business site, my tech site, and my book blog onto my personal emilygertenbach.com website so I have a complete repository of everything I create.
I also knew that I didn’t want the full text of posts on egcreativecontent.com to sync here because I’d wind up competing with myself in certain search results.
Problem 3: Ulysses supports posting to one blog per platform
I thought I could connect multiple micro.blog accounts, but it doesn’t work that way. I could pick one Micro.blog, one Ghost account, etc.
Problem 4: I was maybe getting ahead of myself with trying to spread out content thematically
This led me to my second configuration. While my initial sync-to-LinkedIn plan worked, I didn’t like how the posts looked, so I took that out of the equation.
Problem 5: I didn’t like how content looks when it pushed to LinkedIn
Self explanatory.
Problem 6: I didn’t want to have to create more accounts to distribute content
It turned out that in this case, I was missing a step in using the Fediverse. By connecting my Bluesky account to Bridgy Fed, people can now find me more easily across other social Fediverse platforms like Mastodon
Problem 7: Medium stories perform better when posted directly to the platform vs. imported from a blog
Or so it seems in my admittedly limited testing so far, and this would track with how content and tech platforms tend to work.
I want to use Medium to get more eyeballs on Tiredof.Tech, so I might have to exclude some posts from a true POSSE system by publishing on Medium first, then sharing a link to my followers through my federated blog.
A Possible Solution
I realized that the answer to most of my issues here would be to consolidate my content as follows:
- All business content published on Ghost website
- Select TiredofTech posts published directly to Medium
- Everything else on my personal domain
My new POSSE-ish structure
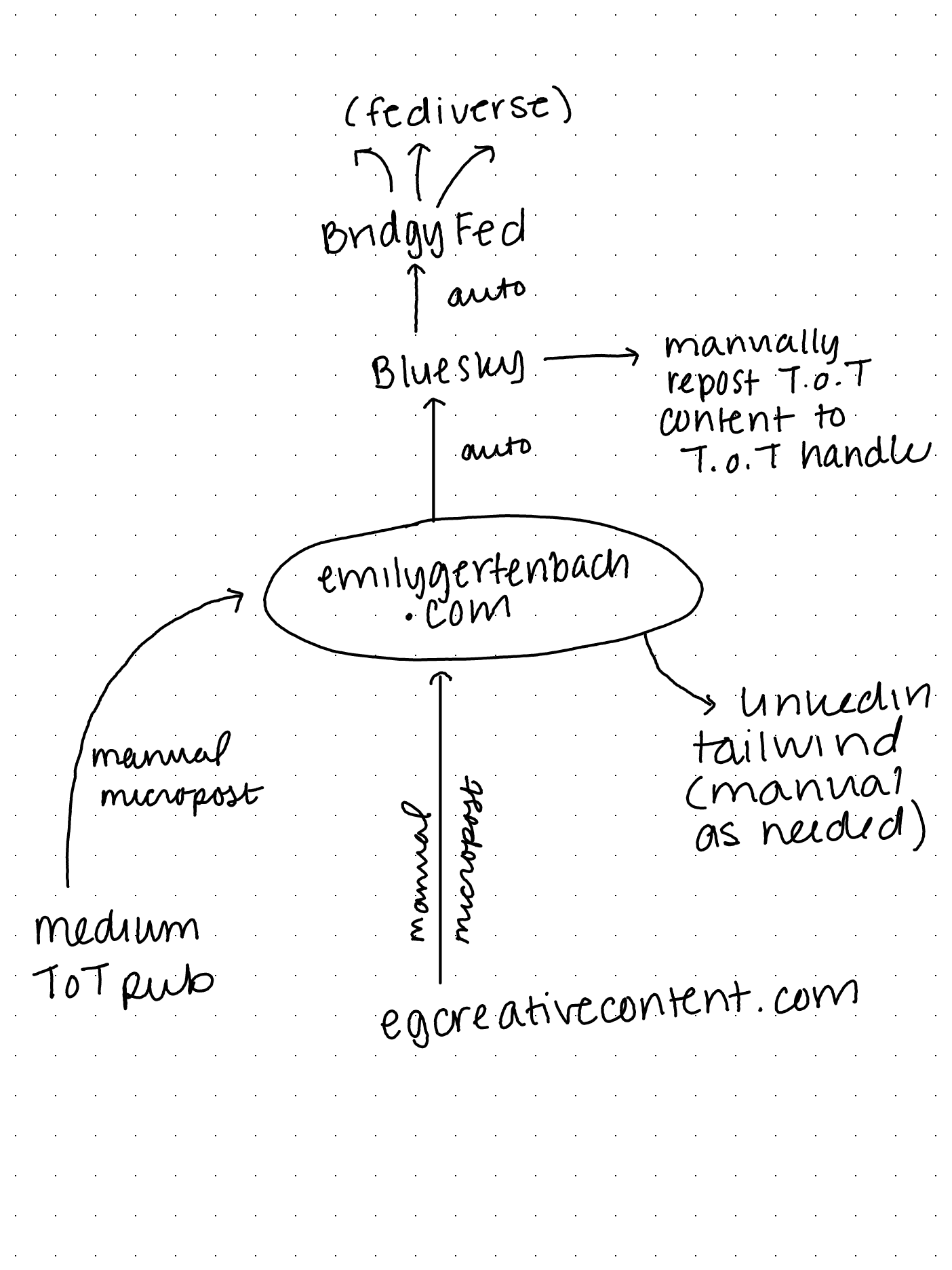
Going forward, I’m going to try:
- Posting business content to my business site, then sharing a link on my personal site
- Posting Tired of Tech content to my Medium page, then sharing a link on my personal site
- Posting any other content, book review, or build in public logs to my personal domain
- Auto-syncing all full posts and shared links from my personal domain to Bluesky
- Auto-syncing the Bluesky feed to the Fediverse via Bridgy Fed
In this configuration, I’m thinking of emilygertenbach.com as the central distribution hub through which content goes in and out. And because Ulysses posts to Medium, I can set up my content workspace so that:
- Drafts in my emilygertenbach.com folder publish to that domain via Micro.blog
- Drafts in my egcreativecontent.com folder publish there via Ghost
- Drafts in my Tiredof.Tech folder publish there via Medium
All my writing is in one spot and it distributes to the correct location with a click.
In total, the tools I’m now using are:
- Ulysses for drafting
- Ghost for my business blog
- Micro.blog for my personal blog
- Medium for selected Tiredof.Tech content
- Carrd for for the actual Tiredof.Tech tool and a book review landing page
- Bluesky to funnel posts from websites into the Fediverse
- Bridgy Fed to do the last-mile connection to other Fed sites like Mastodon
And the actual actions I have to take for this to work are:
- Click publish in Ulysses
- Copy link from business site or Medium and put it in a short update post on my personal domain
- Manually copy and paste links to share on LinkedIn and Pinterest
- Add links to my Tiredof.Tech and book blog homepages as I see fit. (I can do these occasionally in batches if I want.)
Build With Me: POSSE Plan
Post (on your) Own Site, Syndicate Everywhere, or POSSE, is an indie web principle that helps you retain control over your own content. Unsurprisingly, as I’ve been building Tiredof.Tech, owning my own content is very important to me.
My SEO writing and consulting business website is built on Ghost, and this site uses Micro.blog—both federated platforms. (I’ll be adding micro.blogs as subdomains to Tiredof.Tech and my sci-fi book list soon as well).
Because Ghost and Micro.blog work with the fediverse, people can find my content from one platform on the other (or on another fediverse site like Mastodon) without creating new accounts.
But not everyone is plugged into the fediverse—it’s confusing! I’ve been dancing around the edge of it for years and it’s just now finally really making sense to me.
Luckily, because you own your own content when using the fediverse, I can easily share what I write out to closed platforms, too. But my content didn’t originate on those proprietary sites—if one shuts down, my content lives on.
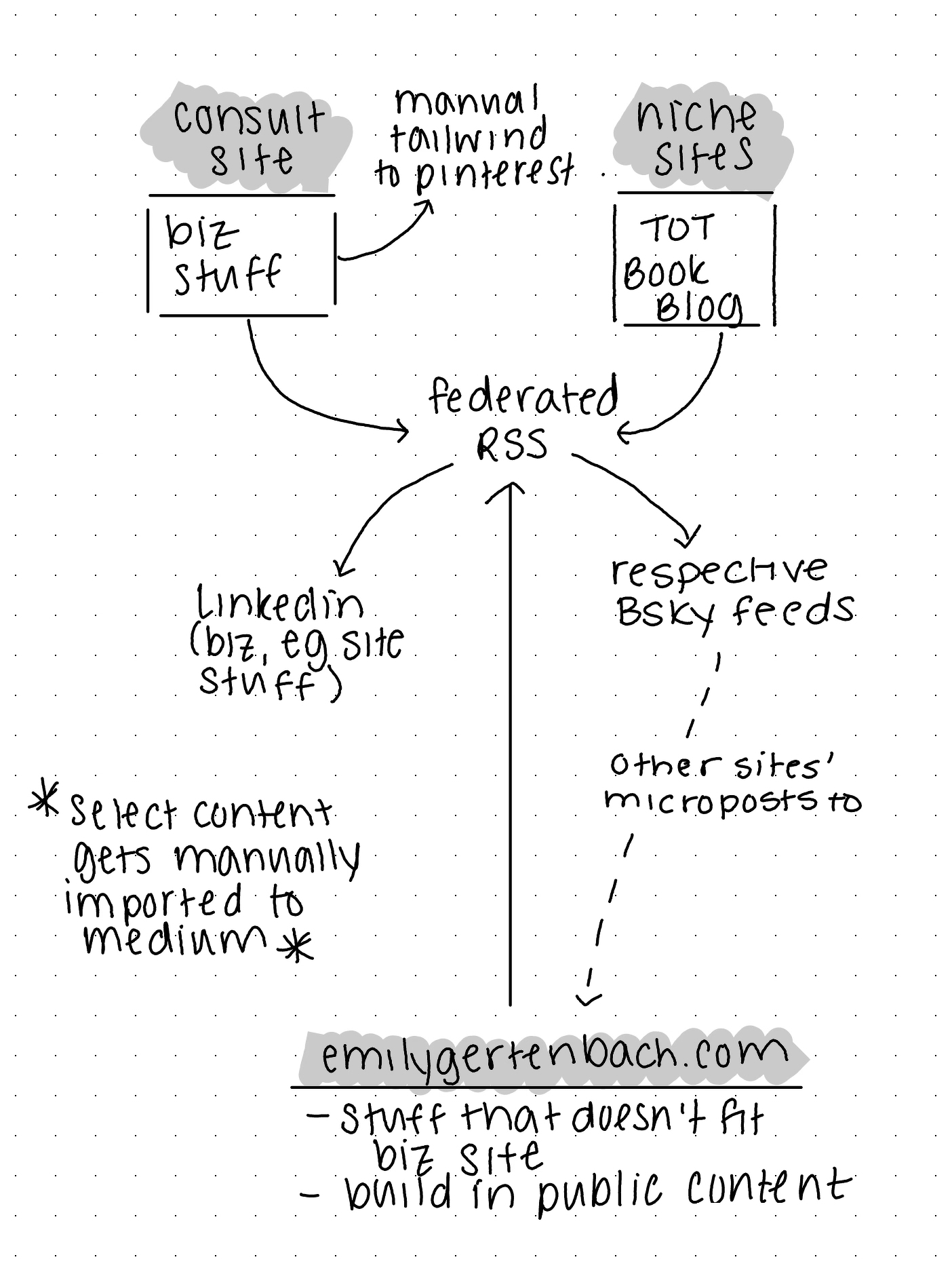
My POSSE plan is as follows:
- Write all of my content using my beloved Ulysses app, which I’ve used for years.
- Publish content directly to the correct Ghost or micro.blog site through Ulysses’ publishing integrations.
- My consulting site and articles from this personal domain get automatically pushed out to LinkedIn.
- Every site’s content gets automatically pushed to its correct Bluesky feed—again, stuff I’ve preconfigured and was posting to manually before.
- My business site, Tiredof.Tech, and book blog Bluesky feeds appear as Tweet-style microposts on emilygertenbach.com, meaning that everything I write can be found when someone searches for me by name. It’ll link out to the original publication site, too, so I won’t be self-competing for SEO.
All of that is supposed to happen automatically based on settings I’ve preconfigured in micro.blog using direct site connections and RSS feeds.
I will then manually post select content to Medium and Tailwind (a Pinterest posting tool).
Whether it works as expected or not, any future learnings I get out of setting up this POSSE process can be found here…or on Bluesky…or on LinkedIn…or on Medium…or wherever you read your content going forward.
Once I get it working, of course!
No, Claude Isn’t Sentient…or Anxious
A Polymarket tweet referencing Dario Amodei of Anthropic — and the company’s model, Claude—has people both nervous and scratching their heads in confusion.
First off, this is an absurd headline. “May or may not?” Come on, pick one.
Second, it’s not a real news alert despite the “BREAKING” tagline. Anyone can say “BREAKING NEWS” and then follow it up with some random string of words. This is a marketing tweet.
What’s Polymarket and why are they talking about Claude?
Polymarket is a platform that allows people to bet money on real-world events, i.e., the likelihood that Claude would become sentient within a certain time frame. An alarmist tweet like the one above could encourage people to bet on something like, oh, I don’t know, whether or not Claude will achieve a certain score on an AI benchmarking exam with a sci-fi sounding name:
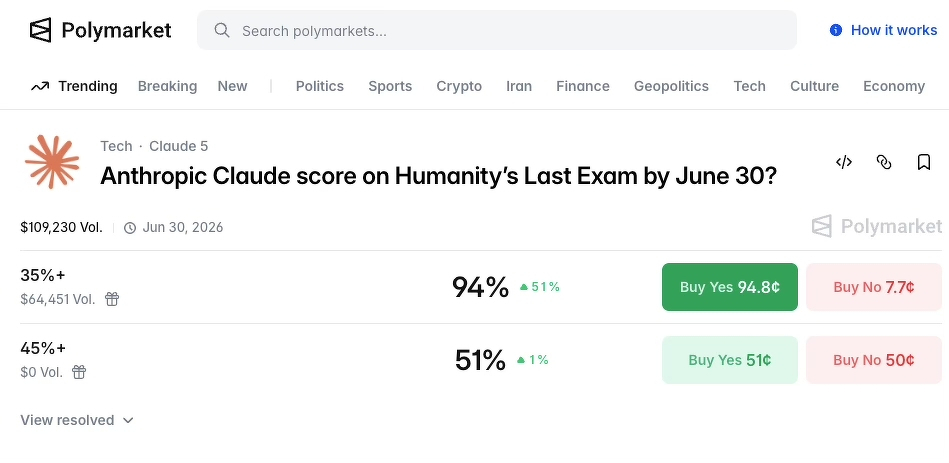
Polymarket’s tweets are an attempt to drive people to the platform and to get these same folks to plunk down their money on speculative betting.
But Polymarket aside, the statement in the tweet — that an AI model showing “signs of anxiety” equals possible sentience—doesn’t hold water, either.
Why an “anxious AI” doesn’t equal sentience
Dario Amodei is interesting from a media perspective. He goes around to different outlets and talks about how scary it is that AI “could be” or “will be” sentient (sometimes giving a vague time frame). And then he goes back to the office and builds the very tool he tells everyone on the morning news circuit to be afraid of.
Dario, my dude, if you’re that worried about AI, just…stop building it.
(Because he doesn’t, I can only assume that his statements of concern are yet another marketing ploy — making Claude out to be the “good” or “sensible” or “safe” AI.)
From what I can tell, the Polymarket tweet is pulling its topic from an interview that Amodei did with the _New York Times. _In this interview, Amodei said that Claude “occasionally voiced discomfort with…being a product” and assigns itself a “15 to 20 percent probability of being conscious under a variety of prompting conditions.”
While this sounds alarming on the surface, once you know how generative AI chats work, it becomes far less stratospheric and more…silly.
How AI works, and why it “voices discomfort”
Generative AI tools—the generative part is important here—create text based on probability. At a simple level, it works like this:
- A company trains an AI model by feeding a vast amount of data into the machine. As an example, Meta trained its AI by uploading 82TB worth of ebooks. You would need 5,125 Kindle Paperwhites if you wanted to build out your ebook library with the same content.
- All of this data is processed through computer programs and mathematical algorithms to determine what words appear near each other and in what frequency. There are multiple rounds of calculations that take place—you can think of it a bit like a March Madness bracket but for word pairs, not basketball teams.
- Through the application of a process called Natural Language Processing (NLP) and parameters set by the company behind the AI, the model gets a “voice” that maintains certain qualities set by the company while mimicking normal human speech patterns. This is what lets the AI’s responses go from “bird is blue and related to crow” to “Yes! You’re right, bluejays are kind of like blue crows—they’re all in the corvid family, after all!”
(I also want to note that depending on the learning process used, humans can be involved, too. Many major AI tech companies outsource data labeling, which includes tasks like identifying a chair in thousands of images, to underpaid workers in the global south.)
This means that when you interact with an AI chat tool like Claude, everything (and I mean everything) it shows to you is due to a mathematical calculation of what you‘d expect a human to say based on the predictions it’s gathered from the training process.
That training data includes:
- Countless Reddit posts from people experiencing the gamut of human emotions, including _anxiety around AI _
- Joking social media posts about “being nice to the AI now so they like me when the robots take over”
- Medical information about humans and anxiety
- Science fiction stories
I put the last one in bold because I think it’s an incredibly important component that can be missed a lot in conversations around AI. A BIG portion of these tools’ training information comes from fictional stories, be it books, TV scripts, or movie screenplays.
So Claude expresses discontent about the possiblity of being a machine. That’s literally a key theme in Blade Runner.
You may have seen other sensationalist headlines about AI “always choosing the nuclear option” when playing war games.
So…like the movie War Games. Not to mention the plethora of literature and films about humans choosing the nuclear option.
Remember, AI responses use probability that’s based on what _the user _is most likely to expect as a response if talking to another person. The way someone words their question or communication with the AI can directly influence the outcome.
What to Do When AI News is Scary
Reporting around AI news and developments might be making you feel … nervous.
And that’s exactly how the creators of these tools, their leaders, and even the media outlets publishing headlines like “Claude may or may not be sentient!” want you to feel.
The more nervous you feel, the more you’ll click to read. The more time you’ll spend on page. And if you don’t push back on such vague or outlandish claims-which is hard to do thanks to the way such headlines are structured-then the value of these AI companies rises and rises in terms of valuations, sale prices, and stocks.
But here’s the thing: any time someone talks about artificial general intelligence (AGI) or “possible” AI sentience, they’re engaging in marketing-speak.
Here’s what I want you to remember:
- Fear of AI, of the “robots taking over,” has been a narrative in science fiction entertainment for decades.
- AI tools are trained on lots of fictional content, including a library’s worth of science fiction. Their mathematical, predictive structures make responses in line with sci fi texts common.
- AGI is, in many cases, defined by AI companies as a financial reporting metric not actual achievement of machines replicating and exceeding complete human intelligence.
- Headlines are meant to drive clicks. (Nope, search engine optimization isn’t dead; it’s alive and well. I have a whole business built around it, though I don’t engage in sensationalist click-driving articles.)
The next time you come across a headline about AI that makes you want to throw your hands up and live in the woods far away from anything remotely robotic, take a step back and do these checks.
AI News Check #1: Who’s behind the publication of this headline?
- News outlet: There’s a good chance there’s some sensationalism involved.
- Scientific journal: There could be some truth here; give the paper a read.
- Corporate social media post: Unless you’re connected to a leading AI research firm, don’t take this at face value.
AI News Check #2: Who are the main sources?
- AI company leader: There’s a good chance this person is saying something specific, even if not entirely true, to drive up company valuation or generate media interest during a slump.
- AI investor: This person likely wants or needs their target companies to rise in value, so they’re also trying to drive up its worth and create media interest.
- AI researcher: This could be based in truth. Some researchers are working for corporations, though, so check out their credentials.
AI News Check #3: Are the associated claims quantitative or quantifiable?
Quantitative claims involve numbers, statistics, data, and hard facts. Qualitative claims are more based in feeling.
If I’m trying to market a new dish soap, I will need some quantitative claims about how well it works (“cuts grease 2x faster than leading competitor”) but I’ll also need qualitative information about how test audiences felt when using the product. This helps me shape my marketing campaign.
When you’re presented with a headline like the one pictured below, it’s easy to have a gut reaction that is as if you’ve read a quantitative fact. But this is an entirely qualitative statement-”may or may not,” “begun showing.” There are no facts, figures, or even definitive statements in this. It’s sensationalist for marketing purposes.
- It’s posted by a corporate account, one that has a vested interest in Claude achieving certain performance levels on an upcoming intelligence benchmark test (people who use Polymarket can bet on the outcome of said test).
- It’s quoting, and not even directly, an AI company CEO.
It’s hard to not be overwhelmed and alarmed by the amount of sensational AI “news” passing through our feeds everyday. We already absorb way more information than the human brain can really handle before lunch. But if you can, take a breather and run through those checks.
Or just close your browser and ignore the offending headline. That’s okay too.
Global Day of Unplugging is Happening; This is My Adaptation
The Global Day of Unplugging is a Sabbath-inspired event that encourages people to get offline for 24 hours. It’s flexible, so you can adapt the idea to your needs (and it’s not like any Unplugging Day enforcer is going to knock on your door, anyway — the organizers even say that one hour of unplugging is better than none).
I think the problem with some of the messaging around days like these (and largely from people mentioning it, not the official website itself) is that it seems Prescriptive and Scary.
What if someone needs to reach you but you’ve turned everything off?
What do you mean “tell everyone you’re going offline,” that feels uncomfortable!
All of my books are digital, am I not supposed to read??
But the beauty of it is you can truly make a day of unplugging into something that works for you. You might even find that you like doing it longer-term.
I plan to focus my own Day of Unplugging on removing tech that controls what I see.
This means that if it can serve me ads or change the flow of how I use the tech through its screens and prompts, it’s out for the day. The parameters I’m setting for myself are:
- No iPhones or iPads outside of the parameters on this list. (I will allow myself to stream workout content via the web browser on my computer — not via YouTube but through Move Fitness and Inner Dimension.)
- Set two times a day where I can check my phone for messages and calls: noon and around dinnertime.
- Limit tech use to three tools that I can fully control the flow of information on: a Fiio Snowsky Echo Mini music player, a Barnes and Noble Nook e-reader, and a Supernote Nomad e-ink tablet.
Normally, my iPad is a big time suck for me — I open it up to do some work, draw, or check the news over the weekend and wind up in a Reddit hole. So that’ll be going on the shelf.
And ultimately, if something goes sideways and I have to or wind up using tech that was on the “no” list, it’s okay. I can put it back on the shelf and reset the clock, or congratulate myself on more hours offline in a day than I might’ve had otherwise.
Because Big Tech or not, sometimes it’s just nice to get off the damn internet for a bit.
Global Day of Unplugging is Happening; This is My Adaptation was originally published in Tired of Tech on Medium, where people are continuing the conversation by highlighting and responding to this story.

Waiting on the Robots to Write
47% of people report not seeing any speed gains when using AI for writing. They’re still spending the same amount of time working as before — and in some cases, AI is making these writers slower.
But wait a minute — how can this be the case? We’ve all seen AI spit out content and it’s borderline instantaneous, isn’t it?
No process, big problems
Here’s the issue: while AI can generate text on a page quickly, that text isn’t always usable for your intended purpose. When people sit down to write content with an AI tool, the AI is simply speeding up parts of their existing workflow.
AI won’t turn you into a novelist or journalist overnight. You’re naturally going to bring your existing mindset, processes, and ideas to the AI … and then the tech will speedrun through those elements.
All this means is that if there’s a problem or inefficiency in your process, the AI is just helping you get to that point faster. It’s not negating the issues.
Sometimes, AI even creates more issues in the long run.
How are real people using AI to write website content?
I’m not being a cynical naysayer here — I ran a survey of over 100 professionals in the U.S. to find out what tools they used to create content, how they created that content, and how quickly they could work.
What I found was that:
- 47% of people aren’t seeing speed gains when writing with AI vs. without it.
- 21% of people spend two or more full workdays trying to create content with AI.
- 42% of people skip any sort of manual editing process and go right from prompt to publish when generating AI content.
- 50% of the people who skip editing AI content still spend at least one full workday coaxing usable content out of the tool.
If you don’t know how to structure your blog posts or articles, you’re dealing with an AI that’s making up factually inaccurate statements, and getting the right tone is a problem, well, the AI experience is going to be rough.
Only 26% of people surveyed reported a “much faster” writing process when using AI.
So what’s the solution for low productivity when writing with AI?
The solution is to actually take a step back from AI. Frustrating, I know, especially when you’ve spent money to get the AI tools and licenses in the first place. But without getting a solid system in place for:
- What you need to write
- How you’re going to structure it
- What your brand voice sounds like
- What data points must be included
Then you’re more likely to run the risk of spending more, not less, time trying to coax content out of an AI tool.
Check out my full report on AI and content production timelines for more.
Waiting on the Robots to Write was originally published in Stress-Free SEO on Medium, where people are continuing the conversation by highlighting and responding to this story.